

Data is the basic unit in which statistical information is collected. In our tech driven day and age, data is being collected all around us at every given second. Our Members at HarperDB have created a method to better store, organize, and use this data. Oh, and they named it after their dog!
There are 8 well experienced, fun, friendly and extremely talented individuals that makeup the core team behind HarperDB. This week I was able to gain a little more insight about their amazingly advanced and easy to use software. Whether you are a small garage startup or a large enterprise developer, HarperDB has got the right team, advice and technology to help you organize and perpetually remain connected with the data you're collecting and stay on the path for growth.
Now, coming from someone with little technical-development experience, I'm going to try my best to break down exactly what HarperDB does. Bear with me:
The convergence of SQL and NoSQL solutions is something that has been going on for a while. A typical way to deal with this requirement is multi-model databases. But Stephen Goldberg and Kyle Bernhardy, the masterminds behind HarperDB, decided to explore a new approach.
They felt multi-model was flawed as a design pattern, were frustrated by the performance of data lakes and map reduce solutions, and wanted something that would be ACID compliant. They thought a single model was needed to accommodate all of the above, so they went ahead and created what they call the exploded data model, which is also the basis of their patent.
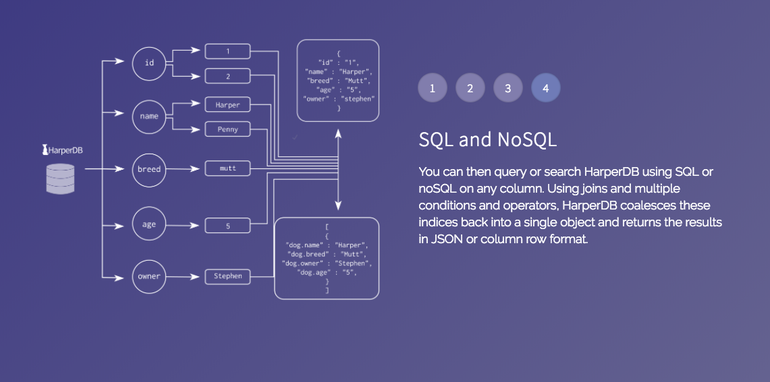
In the exploded data model, each attribute from a JSON object, or column from a SQL insert/update statement becomes an index upon write. These attributes and their values are stored discreetly on disk.
Goldberg and Bernhardy say one of the main goals behind HarperDB was to make it so easy that a developer of any skill level could use it. They wanted to internalize the majority of the complexity of developing a database rather than offloading that complexity onto the developer. They say the install process requires five questions and takes about one or two minutes.
HarperDB's system was created by developers for developers to help guide, strengthen and simplify your data collecting process while keeping you on the path for growth. Their recipe for success is that they aim to “…internalize the complexity of developing a database rather than offloading that complexity onto the developer”. Since releasing the beta in August 2017 they have received fewer than five support requests with nearly 800 downloads from 670+ developers!!
With all of this amateurishly being said, we are certainly proud to call the HarperDB team members of our Community!! They would also love to invite you all to explore and test out their technology for free if you would you would like by just clicking on the link below.
HarperDB Community Edition Trial
